Worker Execution Retry Architecture
Overview
This document specifies how the Alakai dashboard re-runs a failed worker execution. It builds on the generic background-task orchestration pipeline: a retry is just a fresh dispatch of a previously-captured task, re-enqueued to the same SQS → orchestrator → ECS path with an incremented attempt number.
Two design rules shape the whole feature:
coreis the only external entry point. The dashboard authenticates againstcore(it already does, via Google OAuth).coreexposes a single authenticated action — retry — and reads the execution record it needs straight from Redis.orchestratoris an internal orchestration layer and exposes no API for this feature; it only writes execution records as it dispatches and resolves workers.- Dispatch logic lives in one place. A retry does not call a special "re-run" endpoint.
corere-publishes the captured task snapshot to SQS, and the existing consumer dispatches it exactly like an initial run. There is only one dispatch path.
Problem Statement
Worker executions (code implementation, digest, bug-hunter) run in ephemeral ECS tasks and can fail — a worker crashes, the model errors, a repo can't be cloned. Operators need to re-run a failed execution without reconstructing its original input by hand.
Constraints that shape the design:
- The record must be durable. A failure noticed the next morning must still have its
payload to replay. The execution record is therefore stored in Redis with no TTL — it
lives until explicitly deleted. (This is distinct from the orchestrator's separate
TaskStore, which holds the in-flight worker payload with a 2-hour TTL and is deleted once the worker calls back.) - The orchestrator must not be internet-facing. The retry action is owned by
core. - One Redis, one schema.
core(reader) andorchestrator(writer) share the same Redis instance and key scheme through the@alakai/execution-storepackage, so the record format can't drift between them.
Architecture
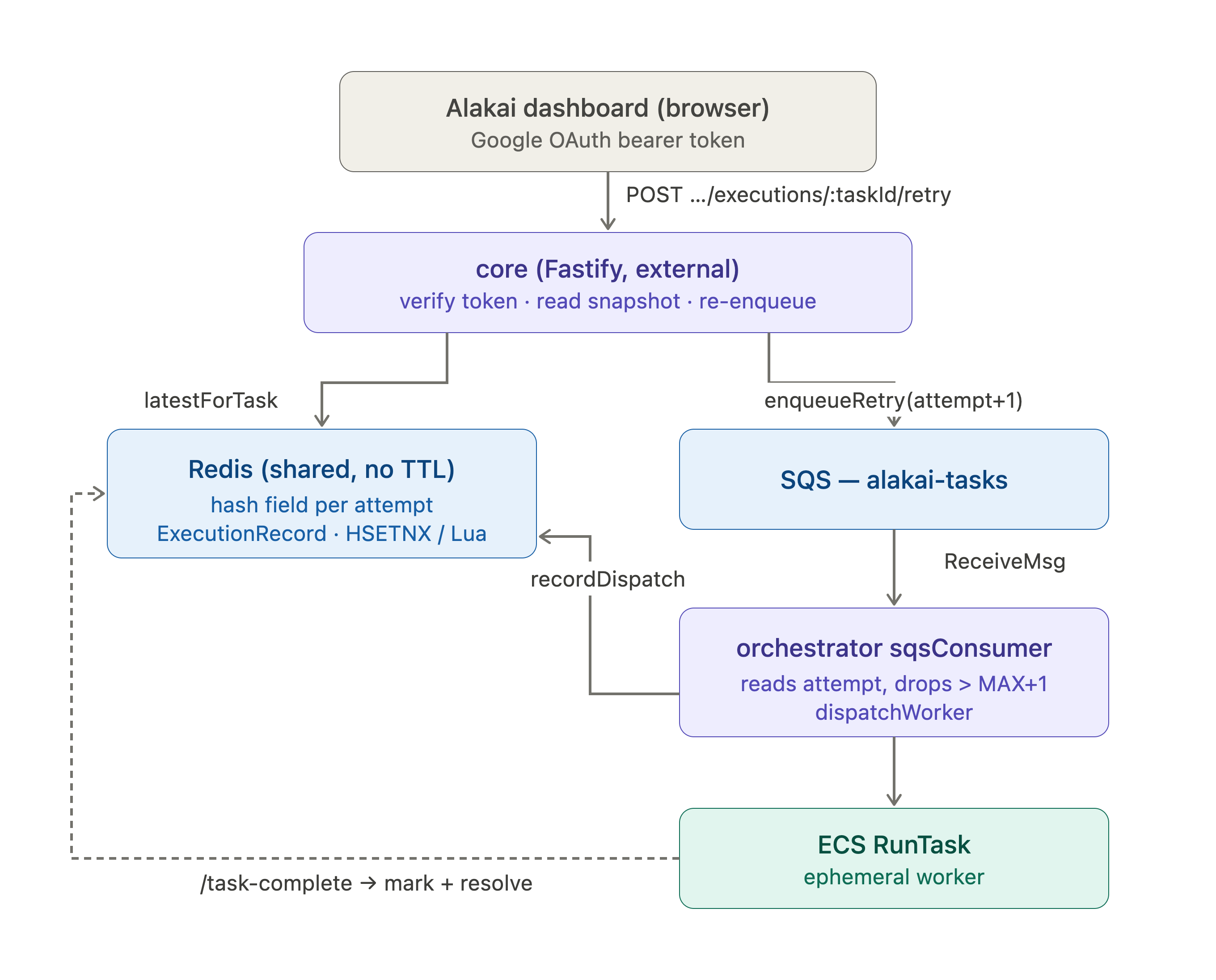
Components
1. core — external dashboard surface
Route (core/src/interfaces/http/routes/executions.ts):
| Endpoint | Method | Behavior |
|---|---|---|
/dashboard/executions/:taskId/retry | POST | Re-enqueue the captured snapshot with attempt+1. 202 on success. |
There is no list/get endpoint — the dashboard already lists failed tasks from its own task tracking, so this surface is retry-only.
requireViewer() runs first → 401 dashboard_unauthorized if the Google identity can't be
resolved. The retry route then enforces, in order:
404if no execution exists,409 cannot retry execution in status '<status>'if the latest isn'tfailed,409 retry budget exhaustedifretryableis false,- then
enqueueRetry(snapshot, attempt+1)→202 { taskId, attempt, status: "queued" }.
A Redis read failure surfaces as 502.
Read service (RedisExecutionsReadService, core/src/infrastructure/executions/): wraps
the shared RedisExecutionStore against TASK_TRACKING_REDIS_URL + EXECUTIONS_REDIS_KEY_PREFIX,
reads the latest attempt, and computes retryable = status === 'failed' && attempt <= MAX_RETRIES
(its MAX_RETRIES mirrors the orchestrator's budget).
Retry publisher (SqsExecutionRetryQueue): enqueueRetry(snapshot, attempt) sends
{ ...snapshot, attempt } to IMPLEMENTATION_SQS_QUEUE_URL with a taskType message
attribute, via the shared sqsClient.ts helper.
2. @alakai/execution-store — shared Redis store
packages/execution-store owns the key scheme and record format for both services, so they
can't drift:
- Layout: one Redis hash per task at
${keyPrefix}:${taskId}, one field per attempt ("1","2", …) whose value is the JSONExecutionRecord(status,attempt,errorCode,errorMessage,taskSnapshot,dispatchedAt,resolvedAt). No TTL. recordDispatch→HSETNX(idempotency gate — see §4).deleteDispatch→HDEL(release a reservation after a failed launch).markSucceeded/markFailed/markLost→ a Lua script that resolves the newest attempt only if it is stillrunning, in a single atomic round trip (the Redis equivalent of the old guarded SQLUPDATE ... WHERE status='running').latestForTask→HGETALL, pick the highest attempt field, parse.
The orchestrator constructs it from REDIS_URL + EXECUTIONS_REDIS_KEY_PREFIX; core from
TASK_TRACKING_REDIS_URL + EXECUTIONS_REDIS_KEY_PREFIX. Both must resolve to the same Redis
instance and prefix.
3. SQS consumer — single dispatch funnel
orchestrator/src/sqs/sqsConsumer.ts resolves the attempt:
attempt = Number.isInteger(task.attempt) && task.attempt > 0 ? task.attempt : 1
- Initial dispatch omits
attempt→ 1. A retry carriesattempt = N+1. - Budget ceiling:
attempt > MAX_RETRIES + 1→ log + delete message (drop). This caps how many attempts may run; a stray or replayed re-enqueue can never exceed the budget. The HSETNX reservation does not enforce the budget — it only dedups a re-used attempt number — so this pre-check must stay. - Calls
dispatchWorker(task, attempt, { launcher, concurrency, store }). - On
DuplicateExecutionError→ idempotent no-op, delete the message (a genuine concurrent duplicate of the same attempt). - On any other launch error → leave the message for SQS redelivery (and eventually the DLQ).
4. dispatchWorker — reserve-then-launch
orchestrator/src/sqs/dispatchWorker.ts is the only launch funnel:
concurrency.tryAcquire(taskId, taskType)— atomic slot acquisition (closes the TOCTOU window). ThrowsNoAvailableSlotErrorat capacity.store.recordDispatch(task, attempt)— writes the(taskId, attempt)record before launch viaHSETNX. This is the idempotency gate: two concurrent messages with the same attempt can't both launch; the loser hits the existing field →DuplicateExecutionError.launcher.launch(task)— ECS RunTask.
On launch failure the reservation is deleted (HDEL, not marked failed) and the slot
released before rethrowing. A launch failure is an infrastructure failure, not a worker
outcome, so the correct retry is SQS redelivery — which can only re-insert the same attempt if
the reservation is gone. Trade-off: launch failures are therefore not surfaced as
dashboard-retryable failed records; that data is reserved for workers that actually ran and
reported failure.
5. Resolving outcomes
Worker callbacks (/task-complete) resolve the record via markSucceeded / markFailed; the
ECS reconciliation loop calls markLost for workers that stopped without calling back. All
three go through the guarded Lua script, so a late or duplicate callback can't clobber a
terminal status.
Data Flow
Retry (happy path)
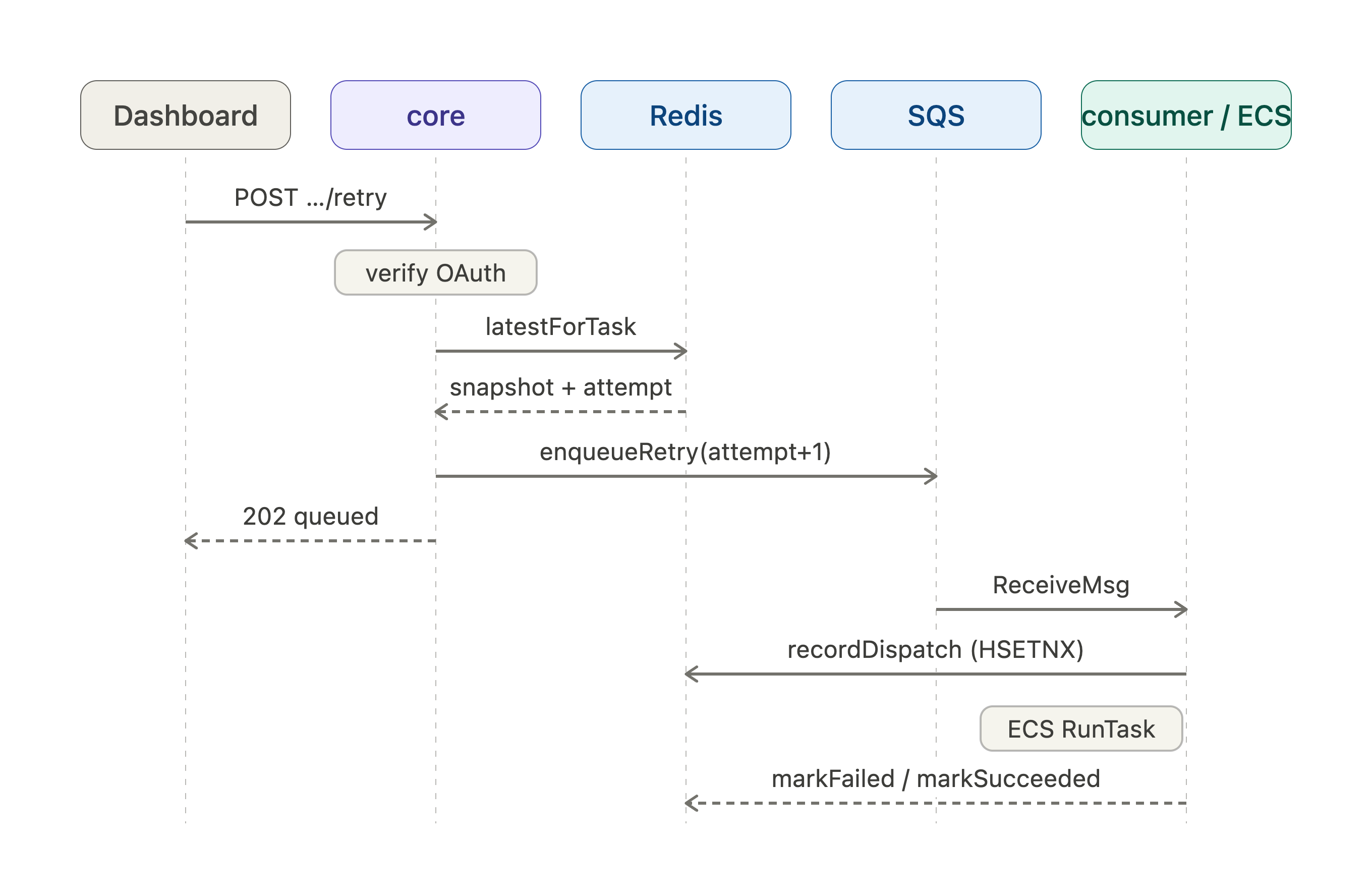
Budget / rejection paths
| Condition | Where | Result |
|---|---|---|
| Not authenticated | core requireViewer | 401 dashboard_unauthorized |
Latest status ≠ failed | core retry route | 409 cannot retry execution in status '<status>' |
retryable === false (budget) | core retry route | 409 retry budget exhausted |
| Redis read fails | core | 502 |
attempt > MAX_RETRIES + 1 reaches the queue anyway | consumer | message dropped (defense in depth) |
Same (task_id, attempt) already reserved | dispatchWorker | DuplicateExecutionError → message deleted, no-op |
Constraints & Invariants
- No external traffic to orchestrator. It exposes no API for this feature;
coreowns the external surface. - One dispatch path. Initial and retry dispatch share SQS → consumer →
dispatchWorker. - Budget is orchestrator-owned.
coresurfacesretryablefor a clean 409; the consumer re-checksattempt > MAX_RETRIES + 1as the authoritative ceiling. - At-least-once + idempotent. SQS may redeliver; the
HSETNXreservation guarantees a given attempt launches at most once. - Launch failure ⇒ reservation rolled back (
HDEL), so redelivery can retry the launch. - Durable replay from Redis. The record (incl.
taskSnapshot) has no TTL and is read back for retry indefinitely. Core and orchestrator MUST share the same Redis instance + key prefix.
Security
- Dashboard → core: Google OAuth ID tokens (
verifyIdToken, audienceTASK_DASHBOARD_GOOGLE_CLIENT_IDS). A local-only bypass (x-dev-user→dev:<value>) is hard-gated toENV === 'local'viawithLocalDevAuthBypass. - core �→ Redis / orchestrator → Redis: both connect to the same in-VPC Redis instance. There is no orchestrator-facing HTTP API and therefore no shared HTTP token to manage; the network boundary is the in-VPC Redis security group.
Configuration
| Service | Var | Required | Notes |
|---|---|---|---|
| core | TASK_TRACKING_REDIS_URL | yes | Redis instance holding the execution records (shared with orchestrator). |
| core | EXECUTIONS_REDIS_KEY_PREFIX | default alakai-executions | MUST match the orchestrator's value. |
| core | MAX_RETRIES | default 1 | Must match the orchestrator's budget; used to compute retryable. |
| orchestrator | REDIS_URL | yes | Same Redis instance as core's TASK_TRACKING_REDIS_URL. |
| orchestrator | EXECUTIONS_REDIS_KEY_PREFIX | default alakai-executions | MUST match core's value. |
| orchestrator | MAX_RETRIES | default 1 | Budget ceiling. retryable and the consumer pre-check both use it. |
Local dev: use x-dev-user to bypass OAuth on the retry route. See
test-worker-execution-retry-locally.md for
the full E2E walkthrough.
Known Follow-ups
These are deliberately deferred (tracked, not blocking):
- Crash-before-launch orphan. If an instance crashes after
recordDispatchwrites the record but before launch succeeds, the field is leftrunning. A redelivery then hitsDuplicateExecutionErrorand is dropped, so the attempt never runs until reconciled. The existing ECS reconciliation is in-memory / instance-scoped and won't catch post-restart orphans. Needs a durable, age-based sweep that marks long-stuckrunningrecords failed. markFailed/markSucceededresolve the newest attempt only. With concurrent attempts (attempt 1 still running while attempt 2 is dispatched), a callback can still resolve the wrong attempt. The attempt should be threaded through the worker callback so each callback resolves its exact attempt.
Related Docs
- background-tasks.md — the generic SQS → orchestrator → ECS pipeline this builds on.
- worker-pipeline.md — chaining workers into multi-step flows.
- test-worker-execution-retry-locally.md — local E2E testing how-to.